Interesting post for purging the dehydration store:
http://www.oracle.com/technetwork/middleware/bpel/learnmore/bpeldehydrationstorepurgestrategies-192217.pdf
Also a simple explanation of High watermark:
http://www.oracle.com/technetwork/middleware/bpel/learnmore/bpeldehydrationstorepurgestrategies-192217.pdf
Showing posts with label SOA. Show all posts
Showing posts with label SOA. Show all posts
Tuesday, December 14, 2010
Tuesday, June 23, 2009
Pitfalls of SOA adoption
An old link about pitfalls of SOA adoption.
Pitfalls of SOA adoption - Thomas ErlMost of the points are still valid, specially the performance impact.
OWSM setup for signature verification
Purpose
Setup OWSM to perform signature validation
Prerequisites
- JKS store should be setup and ready to use. Refer to http://tech-sash.blogspot.com/2009/06/keystore-setup-for-owsm.html for more details.
- OWSM gateway is already created. To create refer http://download-uk.oracle.com/docs/cd/B31017_01/integrate.1013/b31007/gateways.htm
Steps
Step 1: Getting the wsdl URL for the service to be secured.
- Login to the BPEL console.
- Select the process to be secured and copy the wsdl url.
- Move to the WSDL tab.

- Remove the version from the wsdl location. http://server:port/orabpel/domain/BPELProcess1/1.1/BPELProcess1?wsdl to http://server:port/orabpel/domain/BPELProcess1/BPELProcess1?wsdl and copy the new wsdl url. This will ensure the OWSM is always pointing to the latest version of process deployed.
- Remove the version from the endpoint location. http://server:port/orabpel/domain/BPELProcess1/1.1 to http://server:port/orabpel/domain/BPELProcess1 and copy the new endpoint location. This will ensure the OWSM is always pointing to the latest version of process deployed.

To secure a java web service (or any other web service), get the correct web service wsdl URL.
Step 2: Register the web service in
OWSM.
- Login to OWSM.
- Go to PolicyManager --> Register Services. Click on Services.

- Click add new service.

- Insert the required details. Please note enter the correct wsdl URL from step 1.4 without the version and then click next.


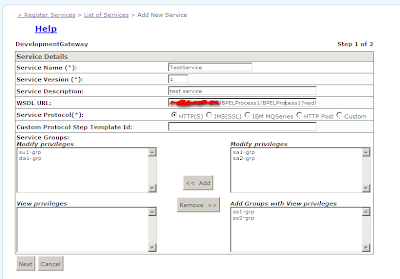
5. Click Finish and then commit.
6. Go back to RegisterSerices --> List Of Services, find the service created and click on edit.

Note the Service URL and the Service Endpoint URL. These will be provided to the client and also used for testing.
7. Click on Modify Policy
8. In the Request pipeline, click on 'Add Step Below' in the Log step and click OK.
 9. Click on configure in the VerifySignature step. Fill in the appropriate values. Use serverpass for the value while creating the keystore and the alias as the value while importing the client certificate.
9. Click on configure in the VerifySignature step. Fill in the appropriate values. Use serverpass for the value while creating the keystore and the alias as the value while importing the client certificate. 10. Click OK and the commit the changes. The update to the signature are done.
10. Click OK and the commit the changes. The update to the signature are done.
Keystore Setup for OWSM
Purpose
keytool -list -keystore [keystore-file.jks] -storepass [serverpass]
Set up the keystore to be used by Oracle Web Services Manager (OWSM) to perform digitial signature validation.
Prerequisites
The client's public key (.cer file) should be provided.
Steps
Step 1: Creating server store.
Use the java keytool command to create a keystore.
keytool -v -genkey -keyalg RSA -keysize 1024 -keystore [keystore-name.jks] -storepass [serverpass]-alias server1 -keypass [server]
Example server output:-
keytool -v -genkey -keyalg RSA -keysize 1024 -keystore server-store-1jks -storepass serverpass -alias server1 -keypass server
What is your first and last name?
[Unknown]: SashCo
What is the name of your organizational unit?
[Unknown]: DPP
What is the name of your organization?
[Unknown]: SashWorld
What is the name of your City or Locality?
[Unknown]: Dubai
What is the name of your State or Province?
[Unknown]: Dubai
What is the two-letter country code for this unit?
[Unknown]: AE
Is CN= SashCo, OU=DPP, O= SashWorld, L=Dubai, ST=Dubai, C=AE correct?
[no]: Y
Generating 1,024 bit RSA key pair and self-signed certificate (MD5WithRSA)
for: CN= SashCo, OU=DPP, O= SashWorld, L=Dubai, ST=Dubai, C=AE
[Storing server-store-1jks]
Step 2
Add the provided public key to the java keystore.
keytool -import -noprompt -trustcacerts -keystore [keystore-file.jks] -storepass [serverpass] -alias [alias] -file [certificate-file.cer]
Example server output:-
keytool -import -noprompt -trustcacerts -keystore server-store-1.jks -storepass serverpass -alias sashwat -file sashwat.cer
Certificate was added to keystore
Step 3:
Use the following command to list the certificates in the .jks file
keytool -list -keystore -storepass
Acronym / Abbreviation
OWSM - Oracle Web Services Manager
keystore-name.jks - Name of the new java keystore
serverpass - password of the keystore
keypass - password of the private key
clientalias - alias for the client
certificate-file.cer - the certificate file provided by client
Helpful Links:-
Java keytool reference :-
Saturday, November 8, 2008
Is your SOA suite is it secure?
I was trying to see if the servers we have is secure enough. What I wanted to know is that wether we were making some errors or the facts were not documented clearly enough. I did find the documentation regarding most problems in some document or the other, but is it clear for admins was the question.
So to find the answer I started looking for SOA suite available online.
Probably this notion would seem stupid why will anyone expose the SOA suite online, I thought that too. But I did an inurl:BPELConsole search and found atleast 10 websites that have their consoles being resulted in the search. Tried a few search engines including google.
The commonly known users are oc4jadmin, but what about bpeladmin and the default users. Nearly 80% of the sites did not have the passwords changed for the users. Could log in some of them seemed to be production sites others were testing sites.
Also a common error was the OWSM user admin with the password as oracle. Sadly most of these users were available to use.
I don't know how to contact the admins of these sites, anyone reading this blog please change the passwords. Go to the user management in the Application Server Console and remove all users that are not used or atleast change the passwords.
All sites had their oc4jadmin passwords changed but it's simply not good enough. Why were these consoles exposed to the internet I have no idea, I don't think it should be done.
Another probability is Denial Of Service attacks or brute force. I don't think (cannot confirm this though) the username for oc4jadmin can be changed. It makes brute force hack even simpler.
Is security still an aferthought for organizations !!! This scares me.

One of the sites I could log into. I have tried to remove all the information regarding who owns the site.
So to find the answer I started looking for SOA suite available online.
Probably this notion would seem stupid why will anyone expose the SOA suite online, I thought that too. But I did an inurl:BPELConsole search and found atleast 10 websites that have their consoles being resulted in the search. Tried a few search engines including google.
The commonly known users are oc4jadmin, but what about bpeladmin and the default users. Nearly 80% of the sites did not have the passwords changed for the users. Could log in some of them seemed to be production sites others were testing sites.
Also a common error was the OWSM user admin with the password as oracle. Sadly most of these users were available to use.
I don't know how to contact the admins of these sites, anyone reading this blog please change the passwords. Go to the user management in the Application Server Console and remove all users that are not used or atleast change the passwords.
All sites had their oc4jadmin passwords changed but it's simply not good enough. Why were these consoles exposed to the internet I have no idea, I don't think it should be done.
Another probability is Denial Of Service attacks or brute force. I don't think (cannot confirm this though) the username for oc4jadmin can be changed. It makes brute force hack even simpler.
Is security still an aferthought for organizations !!! This scares me.

One of the sites I could log into. I have tried to remove all the information regarding who owns the site.
Saturday, November 1, 2008
Learning and implementing the Oracle Fault Management Framework
Why?
The process has some external dependencies, due to a network failure the partner system is down for a few days. The message sent to the partner can be sent later but recovery mechnism can be difficult and redundant in BPEL.
How was it done before?
Without the framework solutions that were possible were
1. Assume that the partner system link or the system would rarely be down, in such cases the process would have to be handled manually. Data fix, using the test case feature etc. This is called wishful thinking.
2. Retry then create a worklist task whenever there is error, requires programming effort and redundancy in process.
3. Rollback using compensation handler may be an option based on design of your process.
What is it in a nutshell?
Instead of handling faults in BPEL by adding catches handle faults use the framework to handle it for you. Both can also be used together. Retry of failed activity, Replay of failed activity scope, Human intervention and many other ways of handling the faults can be provided.
In detail it can be read fro references stated below.
What is the advantage?
1. Generic framework can be reused without coding effort.
2. Will provide resume, retry, continue and modify functionalities.
3. No BPEL change required
Lessons learnt and opinions
While implement the fault handling using this framework, found rather suprisingly that it was very easy to use. The only trouble I had was that in my patch of 10.1.3.3 the post installation steps had not been executed. Without these steps the framework does not catch the fault.
It was rather suprising that the framework can override the fault handling defined in the process. It was a bit difficult to digest but I could not think of any way else it could be designed.
The best resource I could find was http://www.it-eye.nl/weblog/2007/09/10/oracle-bpel-10133-fault-policy-management/
A very good resource to begin.
Also use Oracle documentation http://www.oracle.com/technology/products/ias/bpel/pdf/10133technotes.pdf is of great help.
Using these resources when I started testing my processes I wanted all my faults remote faults to be retried and then sent for human intervention.
But then I started facing issues when an synchronous process is invoked and the process waiting for human intervention the calling process is timed out. So I had to have a seperate policy for synchronous processes which only contain retries and another for asynchronous processes which contain retry and human intervention.
This reminded me of some Oracle document which had said prefer Async process over sync (I think it said it because of performance reasons).
Then I stumbled over an article http://orasoa.blogspot.com/2008/03/bpel-fault-policies-best-practise.html which validated my understandings.
If this works(in production) I'm pretty sure it will (It's working on my PC but cannot celebrate until it goes to production) I will be very pleased.
The framework has limited extensibility only java tasks can be used to extend the framework. It leaves very less scope for out of the box thinking.
Also, the problem I faced was that the activities tab in the BPEL Console needs to be provided to support personnel, none of the other tabs should be accessible. Could not resolve this issue :(. From the information I could gather was that this can only be done by tweaking the code of BPEL Console. ref: http://chintanblog.blogspot.com/2007/12/i-saw-numerous-people-asking-about-bpel_290.html
Special thanks:
To the Oracle team to come up with this feature and the blogs of consultants I have mentioned and all the people who answer questions on the Oracle forum.
The process has some external dependencies, due to a network failure the partner system is down for a few days. The message sent to the partner can be sent later but recovery mechnism can be difficult and redundant in BPEL.
How was it done before?
Without the framework solutions that were possible were
1. Assume that the partner system link or the system would rarely be down, in such cases the process would have to be handled manually. Data fix, using the test case feature etc. This is called wishful thinking.
2. Retry then create a worklist task whenever there is error, requires programming effort and redundancy in process.
3. Rollback using compensation handler may be an option based on design of your process.
What is it in a nutshell?
Instead of handling faults in BPEL by adding catches handle faults use the framework to handle it for you. Both can also be used together. Retry of failed activity, Replay of failed activity scope, Human intervention and many other ways of handling the faults can be provided.
In detail it can be read fro references stated below.
What is the advantage?
1. Generic framework can be reused without coding effort.
2. Will provide resume, retry, continue and modify functionalities.
3. No BPEL change required
Lessons learnt and opinions
While implement the fault handling using this framework, found rather suprisingly that it was very easy to use. The only trouble I had was that in my patch of 10.1.3.3 the post installation steps had not been executed. Without these steps the framework does not catch the fault.
It was rather suprising that the framework can override the fault handling defined in the process. It was a bit difficult to digest but I could not think of any way else it could be designed.
The best resource I could find was http://www.it-eye.nl/weblog/2007/09/10/oracle-bpel-10133-fault-policy-management/
A very good resource to begin.
Also use Oracle documentation http://www.oracle.com/technology/products/ias/bpel/pdf/10133technotes.pdf is of great help.
Using these resources when I started testing my processes I wanted all my faults remote faults to be retried and then sent for human intervention.
But then I started facing issues when an synchronous process is invoked and the process waiting for human intervention the calling process is timed out. So I had to have a seperate policy for synchronous processes which only contain retries and another for asynchronous processes which contain retry and human intervention.
This reminded me of some Oracle document which had said prefer Async process over sync (I think it said it because of performance reasons).
Then I stumbled over an article http://orasoa.blogspot.com/2008/03/bpel-fault-policies-best-practise.html which validated my understandings.
If this works(in production) I'm pretty sure it will (It's working on my PC but cannot celebrate until it goes to production) I will be very pleased.
The framework has limited extensibility only java tasks can be used to extend the framework. It leaves very less scope for out of the box thinking.
Also, the problem I faced was that the activities tab in the BPEL Console needs to be provided to support personnel, none of the other tabs should be accessible. Could not resolve this issue :(. From the information I could gather was that this can only be done by tweaking the code of BPEL Console. ref: http://chintanblog.blogspot.com/2007/12/i-saw-numerous-people-asking-about-bpel_290.html
Special thanks:
To the Oracle team to come up with this feature and the blogs of consultants I have mentioned and all the people who answer questions on the Oracle forum.
Tuesday, May 20, 2008
WS-BPEL 2.0
Derived from : http://docs.oasis-open.org/wsbpel/2.0/Primer/wsbpel-v2.0-Primer.pdf
Copyright © OASIS Open 2007. All Rights Reserved.
This document and translations of it may be copied and furnished to others, and derivative works that comment on or otherwise explain it or assist in its implementation may be prepared, copied, published and distributed, in whole or in part, without restriction of any kind, provided that the above copyright notice and this paragraph are included on all such copies and derivative works. However, this document itself may not be modified in any way, such as by removing the copyright notice or references to OASIS, except as needed for the purpose of developing OASIS specifications, in which case the procedures for copyrights defined in the OASIS Intellectual Property Rights document must be followed, or as required to translate it into languages other than English.
What’s new in WS-BPEL 2.0
As a result of the OASIS Technical Committee’s issues process, the original BPEL4WS 1.1 specification has received several updates. The following list summarizes the major changes that have been incorporated in the WS-BPEL 2.0 specification.
Data Access
Most of the features added seems to be lessons learn't, a good way to improve. It does not drastically change the specifications but seems to be more friendly for the developer. Many problems that I am facing with the current implementation with BPEL 1.1 would be removed using this specification when the product vendor decides to implement it.
Sadly one point was missing support for XPath 2.0 and XSLT 2.0. The FAQs [http://www.oasis-open.org/committees/download.php/23858/WS-BPEL-2.0-FAQ.html] clearly state 'WS-BPEL2.0 is based upon XPath 1.0 and XSLT 1.0'. I thought XSLT 2.0 and XPath 2.0 were huge advancements but not being supported I was very disappointed. I believe the product vendors would still support them along with XPath 1.0 and XSLT 1.0 as standard extensions.
Copyright © OASIS Open 2007. All Rights Reserved.
This document and translations of it may be copied and furnished to others, and derivative works that comment on or otherwise explain it or assist in its implementation may be prepared, copied, published and distributed, in whole or in part, without restriction of any kind, provided that the above copyright notice and this paragraph are included on all such copies and derivative works. However, this document itself may not be modified in any way, such as by removing the copyright notice or references to OASIS, except as needed for the purpose of developing OASIS specifications, in which case the procedures for copyrights defined in the OASIS Intellectual Property Rights document must be followed, or as required to translate it into languages other than English.
What’s new in WS-BPEL 2.0
As a result of the OASIS Technical Committee’s issues process, the original BPEL4WS 1.1 specification has received several updates. The following list summarizes the major changes that have been incorporated in the WS-BPEL 2.0 specification.
Data Access
- Variables can now be declared using XML schema complex types
- Access to WSDL messages has been simplified by mapping directly mapping WSDL message parts to XML schema element/type variables
- Several clarifications have been added to the description of the
activity’s semantics
- The keepSrcElementName option has been added to
in order to support XSD substitution groups or choices
- The ignoreMissingFromData has been added to automatically some of
operation, when the from data is missing.
- An extension operation has been added to the
activity
- A standardized XSLT 1.0 function has been added to XPath expressions
- The ability to validate XML data has been added, both as an option of the
activity and as a new activity
- Variable initialization as part the of variable declaration has been added
- New scope snapshot semantics have been defined
- Fault handling during compensation has been clarified
- The interaction between scope isolation and control links have been clarified
- A
activity has been added to fault handlers
- The
has been added to scopes
- The exitOnStandardFault option has been added to processes and scopes
- The join option has been added to correlation sets in order to allow multiple participants to rendezvous at the same process with a deterministic order
- Partner link can now be declared local to a scope
- The initializePartnerRole option has been added to specify whether an endpoint reference must be bound to a partner link during deployment
- The messageExchange construct has been added to pair up concurrent
and activities
Most of the features added seems to be lessons learn't, a good way to improve. It does not drastically change the specifications but seems to be more friendly for the developer. Many problems that I am facing with the current implementation with BPEL 1.1 would be removed using this specification when the product vendor decides to implement it.
Sadly one point was missing support for XPath 2.0 and XSLT 2.0. The FAQs [http://www.oasis-open.org/committees/download.php/23858/WS-BPEL-2.0-FAQ.html] clearly state 'WS-BPEL2.0 is based upon XPath 1.0 and XSLT 1.0'. I thought XSLT 2.0 and XPath 2.0 were huge advancements but not being supported I was very disappointed. I believe the product vendors would still support them along with XPath 1.0 and XSLT 1.0 as standard extensions.
Monday, April 21, 2008
Oracle SOA suite - Retrieving process information
The problem statement
To retrieve the information of a process from dehydration store even when I did not have the instance id using data present in the request of the process. (This is a part of a bigger problem I am trying to resolve)
I have an a unique field in the BPEL input. How can I find the BPEL instance and the related instances (This BPEL is executed which in turn executes several other BPEL processes ). I could not modify the existing BPEL so I was left with only one option that was to use the Oracle BPEL Process Manager Client API. This API has very less documentation, most of the help I got was from some blogs specially http://orasoa.blogspot.com/2007/06/calling-bpelesb-webservice-from.html and the API documentation http://download-uk.oracle.com/docs/cd/B31017_01/integrate.1013/b28986/toc.htm.
Driving to the beach
The Marc Kelderman blog solved one of the biggest problems I faced the 'jar hell'. I had tried several other posts but was not successful in setting up the project correctly, but the jar files as specified by him worked wonderfully.
Finally my classpath contained :-
connector15.jar, ejb.jar, oc4j-internal.jar, optic.jar, orabpel.jar, orabpel-ant.jar, orabpel-boot.jar, orabpel-common.jar, orabpel-exts.jar, orabpel-thirdparty.jar, oracle_http_client.jar, orawsdl.jar, xmlparserv2.jar. I am using SOA Suite version 10.1.3.3.
Now I setup a new java project in eclipse with these jars in my classpath. I then setup a server configuration file
Getting your feet wet
Load the properties:-
The next piece of code I wrote was to retrieve all the instances of a specific BPEL process,
Taking the dive
And using the instance handles I could display the states and instance id's of the processes. Now this was just the beginning of learning of how to use the API. I needed to modify it to suite my requirements. The previous piece of code returns all record in no particular order, this would make my task very difficult. By trial and error I realized that the API was using a view admin_list_ci to query and all its fields could be used in the query. Thus I added the following to order by creation_date (My instance would be one of the current instances in the server) desc. The next problem was if there was an error the list would continue processing infinitely. So I decided that my instance would be one of the last 50 instance executed on the server. This was a safe assumption since I would be searching immediately after submission. Thus my code became:-
The next problem to resolve was ho do I find if the given IInstanceHandle handle was the instance I was searching for. I needed to search if my application specific id was present in the request of the instance.
And from the appid compare with the appid we had and keep on looping until the instance is found. Thus I was successful in retrieving the instance id.
To find all the related instances find the current instance and get it's handle. Then use the following where condition to retrieve related instances:-
Conclusion
To retrieve the information of a process from dehydration store even when I did not have the instance id using data present in the request of the process. (This is a part of a bigger problem I am trying to resolve)
I have an a unique field in the BPEL input. How can I find the BPEL instance and the related instances (This BPEL is executed which in turn executes several other BPEL processes ). I could not modify the existing BPEL so I was left with only one option that was to use the Oracle BPEL Process Manager Client API. This API has very less documentation, most of the help I got was from some blogs specially http://orasoa.blogspot.com/2007/06/calling-bpelesb-webservice-from.html and the API documentation http://download-uk.oracle.com/docs/cd/B31017_01/integrate.1013/b28986/toc.htm.
Driving to the beach
The Marc Kelderman blog solved one of the biggest problems I faced the 'jar hell'. I had tried several other posts but was not successful in setting up the project correctly, but the jar files as specified by him worked wonderfully.
Finally my classpath contained :-
connector15.jar, ejb.jar, oc4j-internal.jar, optic.jar, orabpel.jar, orabpel-ant.jar, orabpel-boot.jar, orabpel-common.jar, orabpel-exts.jar, orabpel-thirdparty.jar, oracle_http_client.jar, orawsdl.jar, xmlparserv2.jar. I am using SOA Suite version 10.1.3.3.
Now I setup a new java project in eclipse with these jars in my classpath. I then setup a server configuration file
Getting your feet wet
## server_config.properties
java.naming.factory.initial=com.evermind.server.rmi.RMIInitialContextFactory
java.naming.provider.url=opmn:ormi://someserver.com:6004:oc4j_soadqa/orabpel
java.naming.security.principal=myname
dedicated.connection=true
java.naming.security.credentials=mypwd
prop = new Properties();
InputStream resourceAsStream = BPELManagerControl.class
.getClassLoader().getResourceAsStream("server_config.properties");
prop.load(resourceAsStream);
Locator locator = new Locator("domainname", prop);
WhereCondition whereProcessId = new WhereCondition("process_id = ?");
whereProcessId.setString(1, "myprocessname");
IInstanceHandle[] instanceHandles = locator
.listInstances(whereProcessId);Taking the dive
And using the instance handles I could display the states and instance id's of the processes. Now this was just the beginning of learning of how to use the API. I needed to modify it to suite my requirements. The previous piece of code returns all record in no particular order, this would make my task very difficult. By trial and error I realized that the API was using a view admin_list_ci to query and all its fields could be used in the query. Thus I added the following to order by creation_date (My instance would be one of the current instances in the server) desc. The next problem was if there was an error the list would continue processing infinitely. So I decided that my instance would be one of the last 50 instance executed on the server. This was a safe assumption since I would be searching immediately after submission. Thus my code became:-
Locator locator = new Locator("domainname", prop);
WhereCondition whereProcessId = new WhereCondition("process_id = ?");
whereProcessId.setString(1, "myprocessname");
whereProcessId.append("ORDER BY CI_Creation_Date desc");
IInstanceHandle[] instanceHandles = locator
.listInstances(whereProcessId,0,50);
- The IInstanceHandle object had a getField method which seemed to suite my requirements (get the request variable and get the xml from it), but I realized it could only be used for a process that is not finished, thus had to drop the idea of using this method.
- The only other way to get the data I could find was using the debug and audit xmls. In the BPELConsole along with the flow of the executed instance it also can display the Audit and Debug xmls. Corresponding methods were getAuditTrail and getDebugTrace that gave the dump of the whole BPEL instance data. I decided to use the getAuditTrail as the debug trace referred to the XML as an id (probably a refernce to some other table) which I could not find. Audit trail seemed to be working thus I decided to use it.
String auditTrailXML = instanceHandle.getAuditTrail();
String XPATH = "//event[@label=\"receiveInput\"]/details/text()";
String receiveInput = Utils.xPathEvaluator(auditTrailXML, XPATH);
XPathFactory factory = XPathFactory.newInstance();
XPath xPath = factory.newXPath();
NamespaceContext ctx = new NamespaceContext() {
public String getNamespaceURI(String prefix) {
String uri;
if (prefix.equals("ns1"))
uri = "http://www.sash.com/Schema/Declaration";
else
uri = null;
return uri;
}
public Iterator getPrefixes(String val) {
return null;
}
public String getPrefix(String uri) {
return null;
}
};
xPath.setNamespaceContext(ctx);
String XPATH2 = "//ns1:appid/text()";
XPathExpression xPathExpression = xPath.compile(XPATH2);
String appid = xPathExpression.evaluate(new InputSource(
new StringReader(receiveInput)));
And from the appid compare with the appid we had and keep on looping until the instance is found. Thus I was successful in retrieving the instance id.
To find all the related instances find the current instance and get it's handle. Then use the following where condition to retrieve related instances:-
WhereCondition wpi = new WhereCondition("ROOT_ID=?");
wpi.setString(1, instanceHandle.getRootId());Conclusion
- The whole code was mostly based on trial and error and basic API documentation.
- The API can be very helpful but very difficult to use
- The view admin_list_ci in the BPEL dehydration store can be used to construct the where clause in the query.
- Setting up the project is not very simple. The jars have to be correct.
- Do you want to use the API? Depends on your requirement. I turned to this API when I had no other option and yes I was satisfied as it resolved my problem.
Friday, March 28, 2008
XSLT / XPATH 2.0
In my current project I was trying to replace a java transformation service to an XSLT. I faced some speed breakers. Googling I came to references of XSLT 2.0 which solves the problems that I was encountering.We are using the Oracle SOA suite 10.3.x. the editor (JDeveloper) only supports XSLT 1.0, but the interesting part is that in text editor changing version of XSLT from 1.0 to 2.0 the parser supports the newer version also.
I just needed group by function like the database. In an array I had to do a grouping. XSLT 2.0 brings the new for-each-group construct. This missing feature from the older xslt version had been a major drawback.
Another simple requirement I had was a sum of products. Say I have multiple items and I need to calculate the total price.
<items>
<line_item>
<price>20</price>
<quantity>33</quantity>
</line_item>
<line_item>
<price>10</price>
<quantity>4</quantity>
</line_item>
</items>
To calculate the product (20*33 + 10*4) we can calculate it by using XPath . Evalaution of XPath sum(for $a in (//line_item) return ($a/price * $a/quantity)) gives the result. We can use this in our XSLT to calculate the value. The new version of XSLT/XPath brings in features that were long waited.
Some other features include :
- Output multiple documents from a single transformation
- Type awareness
- The resultant tree created by querying the doc, can be queried like any other element
- custom functions
I hope these standards are adopted soon by everyone with better tool support.
Sunday, November 25, 2007
Non WS-I document literal web service
A document literal web service with more than one parts specified for the same message is not WS-I compliant.
e.g.
The SOAP message would look like:
Why the restriction, think about validation of the message. I would have to extract the name and age elements seperately and then validate them against an XSD. If the elements were within a single tag...
The person element can be completely validated after the person element is extracted.
e.g.
<wsdl:message name="HelloDudeSoapIn">
<wsdl:part name="name" element="tns:name"/>
<wsdl:part name="age" element="tns:age"/>
</wsdl:message>
The SOAP message would look like:
<soap-env:envelope>
<soap-env:body>
<m:name>Baby</m:name>
<m:age>1</m:age>
</soap-env:body>
</soap-env:envelope>
Why the restriction, think about validation of the message. I would have to extract the name and age elements seperately and then validate them against an XSD. If the elements were within a single tag...
<soap-env:envelope>
<soap-env:body>
<m:person>
<m:name>Baby</m:name>
<m:age>1</m:age>
</m:person>
</soap-env:body>
</soap-env:envelope>
The person element can be completely validated after the person element is extracted.
Wednesday, November 14, 2007
XPath injection
XPath injection
What is XPath?XPath (XML Path Language) is an expression language for addressing portions of an XML document, or for computing values (strings, numbers, or boolean values) based on the content of an XML document.
For more information see XPath tutorial.
Understanding the attack
XPath injection is an attack where data is taken from the user without validation (or incomplete validation) and which modifies the behavior of the XPath expression by masquerading XPath as data.Assume that we have user id and password stored in xml files and we use XPath for validating them. The xml containing the user id and password looks like:
<security-check>
<user>
<id>sash</id>
<password>sash123</password>
</user>
<user>
<id>abhinav</id>
<password>abhinav123</password>
</user>
</security-check>
To validate the user id and password against the xml we use the XPath expression
//user[id/text()='+ {input user id} +' and password/text()='+ {input password} +']
we execute the XPath and check if it returns any nodes, if it returns any nodes then the password is valid. If the entered used id is sash and the password is sash123 the XPath would become
//user[id/text()='sash' and password/text()='sash123']
and would return the user node and the password would be validated. If a wrong password is used no node would be returned and the validation would fail.
Now while injecting XPath in the password field ' or 'a' = 'a is entered. The XPath would become
//user[id/text()='sash' and password/text()='' or 'a' = 'a']
which would return multiple rows and the validation would pass.
Simulating the attack
Sample C# codeXmlDocument XmlDoc = new XmlDocument();
XmlDoc.Load("XPATH_INJECT.xml"); // use the same xml as above
XPathNavigator nav = XmlDoc.CreateNavigator();
XPathExpression expr = nav.Compile("//user[id/text()='"
+ textBox1.Text + "' and password/text()='" + textBox2.Text + "']");
XPathNodeIterator iterator = nav.Select(expr);
if (iterator.MoveNext())
{
result.Text = "passed";
}
else
{
result.Text = "failed";
}
Sample Java code
XPathFactory factory = XPathFactory.newInstance();
XPath xPath = factory.newXPath();
File xmlDocument = new File("XPATH_INJECT.xml");
InputSource inputSource = new InputSource(
new FileInputStream(xmlDocument));
String user = jTextField1.getText().trim();
String pwd = jTextField2.getText().trim();
XPathExpression expr = xPath.compile(
"//user[id/text()='" + user +
"' and password/text()='" + pwd +
"' ]");
Object result = expr.evaluate(inputSource, XPathConstants.NODESET);
NodeList nodes = (NodeList) result;
if(nodes.getLength()>0)
{
jLabel3.setText("Valid"); }
else
{
jLabel3.setText("Failed"); }
}
How to protect against the attack:
There are many ways of preventing this attack- Validate the input
- Escape the ' or '' characters
- This attack is similar to SQL injection, the most common solution to SQL injection attack is using a prepared statement, but something similar is not available in XPath. This though can be achieved using XQuery but XQuery is not directly supporeted without the use of external libraries in .Net or Java.
The best solution would be escaping the ['] characters, in our example if we replace a ['] with [']['] in the input, we would avoid the attack.
In the previous case our password text entered was ' or 'a' = 'a but this would be modified to '' or ''a'' = ''a
//user[id/text()='sash' and password/text()=''' or ''a'' = ''a']
and would not produce any results (and it is a valid XPath).
This XPath passes in Altova XML spy but not in Java 6 or .Net 2.0
So we still need to find an elegant solution to the problem!!!!
In all the proposed solutions solution (3) is the most elegant but the support is still very limited.
Whats left
Some of the databases now support XPath, in case your database supports XPath be very careful about the inputs (don't forget the validation).References
http://www.ibm.com/developerworks/xml/library/x-xpathinjection.htmlhttp://www.packetstormsecurity.org/papers/bypass/Blind_XPath_Injection_20040518.pdf
Wednesday, March 14, 2007
The role of Representational State Transfer in Web Based computing
A brief introduction to Representational State Transfer (REST)
REpresentational State Transfer or REST is an architectural style consisting of the set of constraints applied to elements within the network architecture. By examining the impact of each constraint as it is added to the evolving style, the properties induced by the Web’s constraints were identified.
But what does Representational State Transfer mean?
Representation
Resources are first-class objects; “object” is a subtype of “resource”. Resources are retrieved not as character strings or Blobs but as complete representations
A web page is a representation of a resource.
State means application/session state; is maintained as part of the content transferred from client to server back to client, thus any server can potentially continue transaction from the point where it had left off.
Transfer of State
Connectors (client, server, cache, resolver, tunnel) are unrelated to sessions and is an abstract mechanism which mediates communication, coordination, or cooperation among components. State is maintained by being transferred from clients to servers and back to clients.
REST is centered around two design principles:
Resource as URLs. A resource is something like a “business entity” which we wish to expose as a part of an API. Each resource is represented as a unique URL.
Operations as HTTP method. REST leverages the existing HTTP methods, particularly GET, POST, PUT and DELETE.
REST provides a set of architectural constraints that, when applied as a whole, emphasizes scalability of component interactions, generality of interfaces, independent deployment of components, and intermediary components to reduce interaction latency, enforce security, and encapsulate legacy systems.
Role of REST in web based applications
REST's "client-stateless-server" constraint forbids session state on the server. Designing within this constraint promotes the system properties of visibility, reliability, and scalability. But the server-side Web applications wish to provide a great deal of personalization to a single user, so they must choose between two designs. The first is to send a massive amount of state information with each client request, so that each request is context-complete and the server can remain stateless. A second simpler solution favored by application developers and middleware vendors alike is to send a simple user identity token and associate this token with a "user session" object on the server side. The second design directly violates the client-stateless-server constraint. It certainly enables desirable user functionality (especially personalization), but it places tremendous strain on the architecture.
The REST constraints provide scalability; say in a clustered environment if the state of client is maintained at the server side then the state has to be replicated across the servers which will be a huge performance overhead.
An AJAX application does not require full page refresh. The fact that Ajax lets us interact with a server without a full refresh puts the option of a stateful client back on the table. This has profound implications for the architectural possibilities for dynamic immersive Web applications: Because application resource and data resource binding is shifted to the client side, these applications can enjoy the best of both worlds the dynamic, personalized user experience we expect of immersive Web applications and the simple, scalable architecture we expect from RESTful applications.
Because the Ajax application engine is just a file, it's also proxyable. On a large corporate intranet, only a single employee might ever download a particular version of the application's Ajax engine, and everyone else just picks up a cached copy from the intranet gateway. So with regard to application resources, a well-designed Ajax application engine aligns with REST principles and provides significant scalability advantages versus server-side Web applications.
RESTful Web Services
The problem of interoperability is very fundamental and deals with what we call the “accidental architecture” where an organization consists of several different technologies and has to make them interoperable. The simpler the solution less will be the overhead in making such systems interoperable. The fundamental problem the web services world solves is interoperability. The question is whether to use SOAP based Web Services or REST web services.
Despite the lack of vendor support, Representational State Transfer (REST) web services have been very successful. For example, Amazon's web services have both SOAP and REST interfaces, and 85% of the usage is on the REST interface. Compared with other styles of web services, REST is easy to implement and maintain.
The SOAP based web services are standardized and standards have been published for the SOAP based web services. They can be used over several transports layer protocols like HTTP, JMS and FTP. REST makes the web service more WEB based. It uses only the HTTP protocol and thus can’t be used with JMS or FTP.
HTTP is not a transport protocol. SOAP treats HTTP as a transport protocol like TCP. HTTP only exists to carry bits, namely SOAP messages, with or without a method name. HTTP is an application protocol; it doesn't send bits, it transfers representational state.
REST isn't the best solution for every Web service. Data that needs to be secure should not be sent as parameters in URIs. If large amounts of data are used in the URI it can become very difficult to maintain and in extreme cases it can even go out of bounds. In such cases SOAP is a preferable solution. But it's important to try REST first and resort to SOAP only when necessary. This helps keep application development simple and accessible.
Fortunately, the REST philosophy is catching on with developers of Web services. The latest version of the SOAP specification now allows certain types services to be exposed through URIs (although the response is still a SOAP message). Similarly, users of Microsoft .NET platform can publish services so that they use GET requests. All this signifies a shift in thinking about how best to interface Web services.
Developers need to understand that sending and receiving a SOAP message isn't always the best way for applications to communicate. Sometimes a simple REST interface and a plain text response does the trick—and saves time and resources in the process.
Should we use REST ?
Arguments against non-REST designs
They break Web architecture, particularly caching. They don't scale well. They have significantly higher coordination costs
Scaling
What kind of scaling is most important is application-specific. Not all apps are Hotmail, Google, or Amazon Integration between two corporate apps has different scaling and availability needs
The right approach to one isn't necessarily the right approach to the other
The REST argument
A service offered in a REST style will inherently be easier to consume than some complex API:
• Lower learning curve for the consumer
• Lower support overhead for the producer
What if REST is not enough?
What happens when you need application semantics that don't fit into the GET / PUT / POST / DELETE generic interfaces and representational state model?
Nearly all the applications can fit into the GET / PUT / POST / DELETE resources / representations model. These interfaces are sufficiently general. Other interfaces considered harmful because they increase the costs of consuming particular services.
Asynchronous operations
There is no complete solution for asynchronous operations available for REST.
Notifications can be sent back as POSTs (the client can implement a trivial HTTP server). Piggyback them on the responses to later requests.
Transactions
The client is ultimately responsible for maintaining the transactions. Other designs for REST aren't much better.
The beginning
The use of REST is on the rise. The ease of use and scalability of the REST based applications stand apart. REST is the beginning of the next generation of Web based computing.
REpresentational State Transfer or REST is an architectural style consisting of the set of constraints applied to elements within the network architecture. By examining the impact of each constraint as it is added to the evolving style, the properties induced by the Web’s constraints were identified.
But what does Representational State Transfer mean?
Representation
Resources are first-class objects; “object” is a subtype of “resource”. Resources are retrieved not as character strings or Blobs but as complete representations
A web page is a representation of a resource.
State means application/session state; is maintained as part of the content transferred from client to server back to client, thus any server can potentially continue transaction from the point where it had left off.
Transfer of State
Connectors (client, server, cache, resolver, tunnel) are unrelated to sessions and is an abstract mechanism which mediates communication, coordination, or cooperation among components. State is maintained by being transferred from clients to servers and back to clients.
REST is centered around two design principles:
Resource as URLs. A resource is something like a “business entity” which we wish to expose as a part of an API. Each resource is represented as a unique URL.
Operations as HTTP method. REST leverages the existing HTTP methods, particularly GET, POST, PUT and DELETE.
REST provides a set of architectural constraints that, when applied as a whole, emphasizes scalability of component interactions, generality of interfaces, independent deployment of components, and intermediary components to reduce interaction latency, enforce security, and encapsulate legacy systems.
Role of REST in web based applications
REST's "client-stateless-server" constraint forbids session state on the server. Designing within this constraint promotes the system properties of visibility, reliability, and scalability. But the server-side Web applications wish to provide a great deal of personalization to a single user, so they must choose between two designs. The first is to send a massive amount of state information with each client request, so that each request is context-complete and the server can remain stateless. A second simpler solution favored by application developers and middleware vendors alike is to send a simple user identity token and associate this token with a "user session" object on the server side. The second design directly violates the client-stateless-server constraint. It certainly enables desirable user functionality (especially personalization), but it places tremendous strain on the architecture.
The REST constraints provide scalability; say in a clustered environment if the state of client is maintained at the server side then the state has to be replicated across the servers which will be a huge performance overhead.
An AJAX application does not require full page refresh. The fact that Ajax lets us interact with a server without a full refresh puts the option of a stateful client back on the table. This has profound implications for the architectural possibilities for dynamic immersive Web applications: Because application resource and data resource binding is shifted to the client side, these applications can enjoy the best of both worlds the dynamic, personalized user experience we expect of immersive Web applications and the simple, scalable architecture we expect from RESTful applications.
Because the Ajax application engine is just a file, it's also proxyable. On a large corporate intranet, only a single employee might ever download a particular version of the application's Ajax engine, and everyone else just picks up a cached copy from the intranet gateway. So with regard to application resources, a well-designed Ajax application engine aligns with REST principles and provides significant scalability advantages versus server-side Web applications.
RESTful Web Services
The problem of interoperability is very fundamental and deals with what we call the “accidental architecture” where an organization consists of several different technologies and has to make them interoperable. The simpler the solution less will be the overhead in making such systems interoperable. The fundamental problem the web services world solves is interoperability. The question is whether to use SOAP based Web Services or REST web services.
Despite the lack of vendor support, Representational State Transfer (REST) web services have been very successful. For example, Amazon's web services have both SOAP and REST interfaces, and 85% of the usage is on the REST interface. Compared with other styles of web services, REST is easy to implement and maintain.
The SOAP based web services are standardized and standards have been published for the SOAP based web services. They can be used over several transports layer protocols like HTTP, JMS and FTP. REST makes the web service more WEB based. It uses only the HTTP protocol and thus can’t be used with JMS or FTP.
HTTP is not a transport protocol. SOAP treats HTTP as a transport protocol like TCP. HTTP only exists to carry bits, namely SOAP messages, with or without a method name. HTTP is an application protocol; it doesn't send bits, it transfers representational state.
REST isn't the best solution for every Web service. Data that needs to be secure should not be sent as parameters in URIs. If large amounts of data are used in the URI it can become very difficult to maintain and in extreme cases it can even go out of bounds. In such cases SOAP is a preferable solution. But it's important to try REST first and resort to SOAP only when necessary. This helps keep application development simple and accessible.
Fortunately, the REST philosophy is catching on with developers of Web services. The latest version of the SOAP specification now allows certain types services to be exposed through URIs (although the response is still a SOAP message). Similarly, users of Microsoft .NET platform can publish services so that they use GET requests. All this signifies a shift in thinking about how best to interface Web services.
Developers need to understand that sending and receiving a SOAP message isn't always the best way for applications to communicate. Sometimes a simple REST interface and a plain text response does the trick—and saves time and resources in the process.
Should we use REST ?
Arguments against non-REST designs
They break Web architecture, particularly caching. They don't scale well. They have significantly higher coordination costs
Scaling
What kind of scaling is most important is application-specific. Not all apps are Hotmail, Google, or Amazon Integration between two corporate apps has different scaling and availability needs
The right approach to one isn't necessarily the right approach to the other
The REST argument
A service offered in a REST style will inherently be easier to consume than some complex API:
• Lower learning curve for the consumer
• Lower support overhead for the producer
What if REST is not enough?
What happens when you need application semantics that don't fit into the GET / PUT / POST / DELETE generic interfaces and representational state model?
Nearly all the applications can fit into the GET / PUT / POST / DELETE resources / representations model. These interfaces are sufficiently general. Other interfaces considered harmful because they increase the costs of consuming particular services.
Asynchronous operations
There is no complete solution for asynchronous operations available for REST.
Notifications can be sent back as POSTs (the client can implement a trivial HTTP server). Piggyback them on the responses to later requests.
Transactions
The client is ultimately responsible for maintaining the transactions. Other designs for REST aren't much better.
The beginning
The use of REST is on the rise. The ease of use and scalability of the REST based applications stand apart. REST is the beginning of the next generation of Web based computing.
Subscribe to:
Posts (Atom)